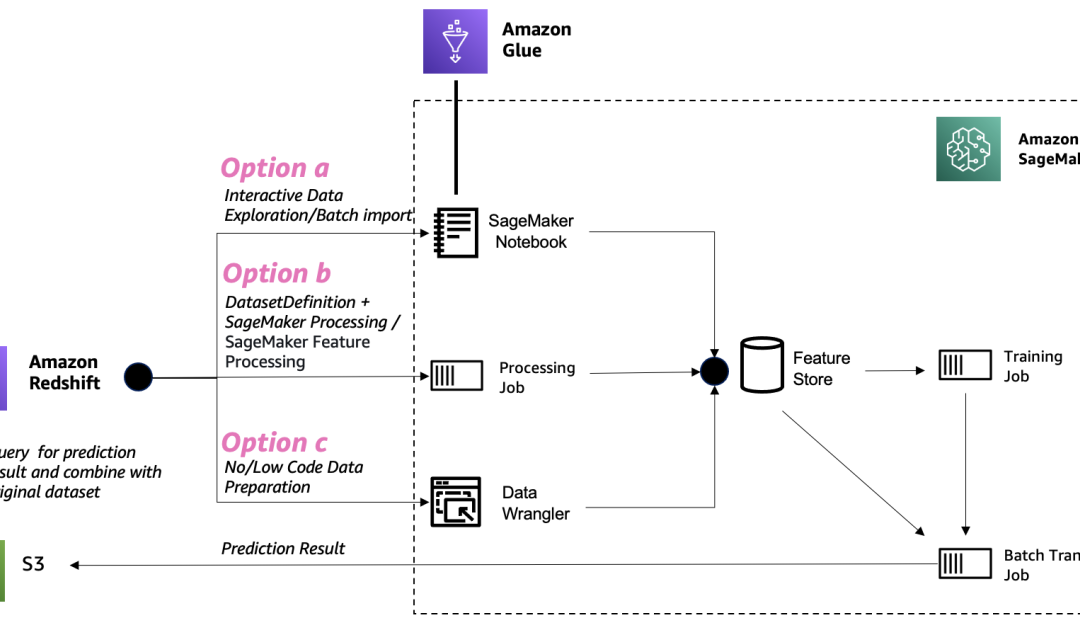
Amazon Redshift is a widely used cloud data warehouse that enables customers to analyze large amounts of data on a daily basis. Many users of Redshift are now looking to extend their datasets for machine learning purposes using Amazon SageMaker. In this post, we will explore three options for preparing Redshift source data at scale in SageMaker.
Option A: AWS Glue
If you are an AWS Glue user and prefer an interactive approach, this option is for you. It allows you to process Redshift datasets in an interactive manner using AWS Glue.
Option B: SageMaker with Spark Code
For users familiar with SageMaker and writing Spark code, this option provides the flexibility to develop features offline using code. You can load data from Redshift, perform feature engineering, and ingest features into the SageMaker Feature Store.
Option C: Low-Code/No-Code Approach
If you prefer a low-code or no-code approach, this option is suitable for you. It allows you to prepare Redshift source data at scale in SageMaker without the need for extensive coding.
Amazon Redshift is designed to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes. It utilizes AWS-designed hardware and machine learning capabilities to deliver excellent price-performance at any scale.
SageMaker Studio is a fully integrated development environment (IDE) for machine learning. It provides a web-based visual interface where you can perform all steps of ML development, including data preparation, model building, training, and deployment.
AWS Glue is a serverless data integration service that simplifies the process of discovering, preparing, and combining data for analytics, machine learning, and application development. It offers various capabilities, including built-in transforms, to seamlessly collect, transform, cleanse, and prepare data for storage in data lakes and data pipelines.
To deploy the solution, you need to create the required AWS resources using an AWS CloudFormation template. The template creates a SageMaker domain, an associated Amazon Elastic File System (Amazon EFS) volume, authorized users, security configurations, a Redshift cluster, a Redshift secret, an AWS Glue connection for Redshift, and an AWS Lambda function to set up required resources.
After deploying the CloudFormation template, you can launch your SageMaker Studio domain and download the GitHub repository containing the necessary notebooks for this solution.
The notebooks guide you through the process of setting up batch ingestion with the Spark connector, setting up the schema and loading data to Amazon Redshift, creating feature stores in SageMaker Feature Store, and performing feature engineering and ingesting features into SageMaker Feature Store.
Option A utilizes a serverless AWS Glue interactive session in SageMaker Studio to perform the feature engineering tasks.
Option B involves using a SageMaker Processing job with Spark to load the dataset from Redshift, perform feature engineering, and ingest the data into the SageMaker Feature Store. This option provides a native Spark way to implement an end-to-end data pipeline from Redshift to SageMaker.
In Option C, a low-code/no-code approach is used to perform feature engineering and ingest processed features into the SageMaker Feature Store.
These options provide flexibility and scalability for preparing Redshift source data at scale in SageMaker, catering to different user preferences and requirements.